Showing 111 of 111on this page. Filters & sort apply to loaded results; URL updates for sharing.111 of 111 on this page
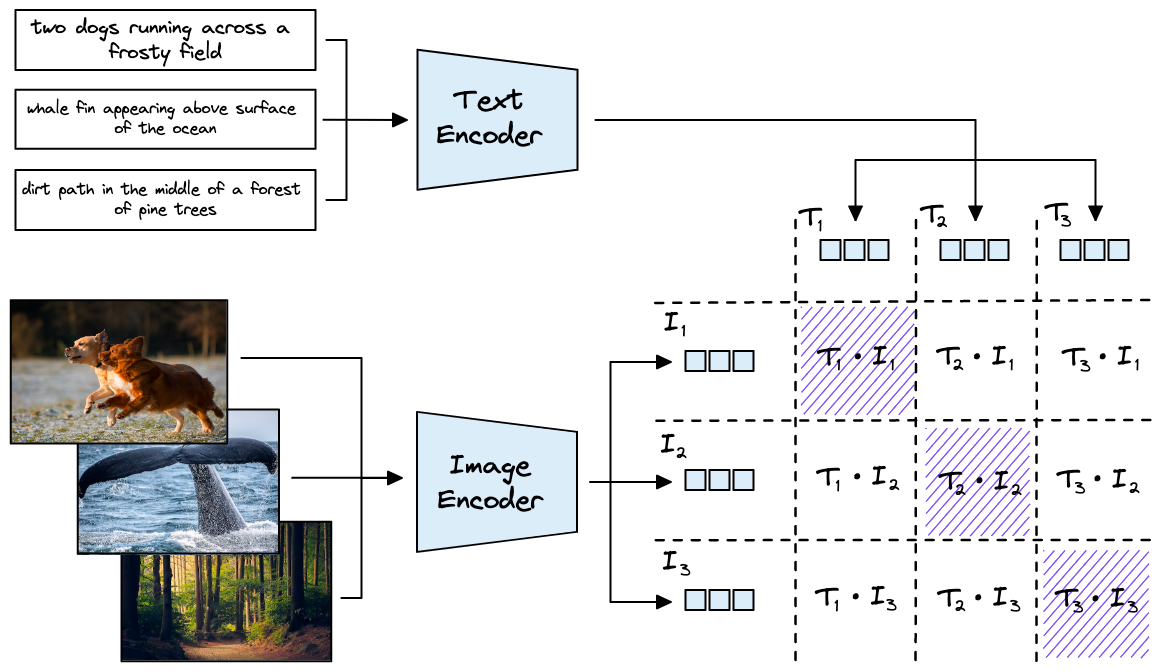
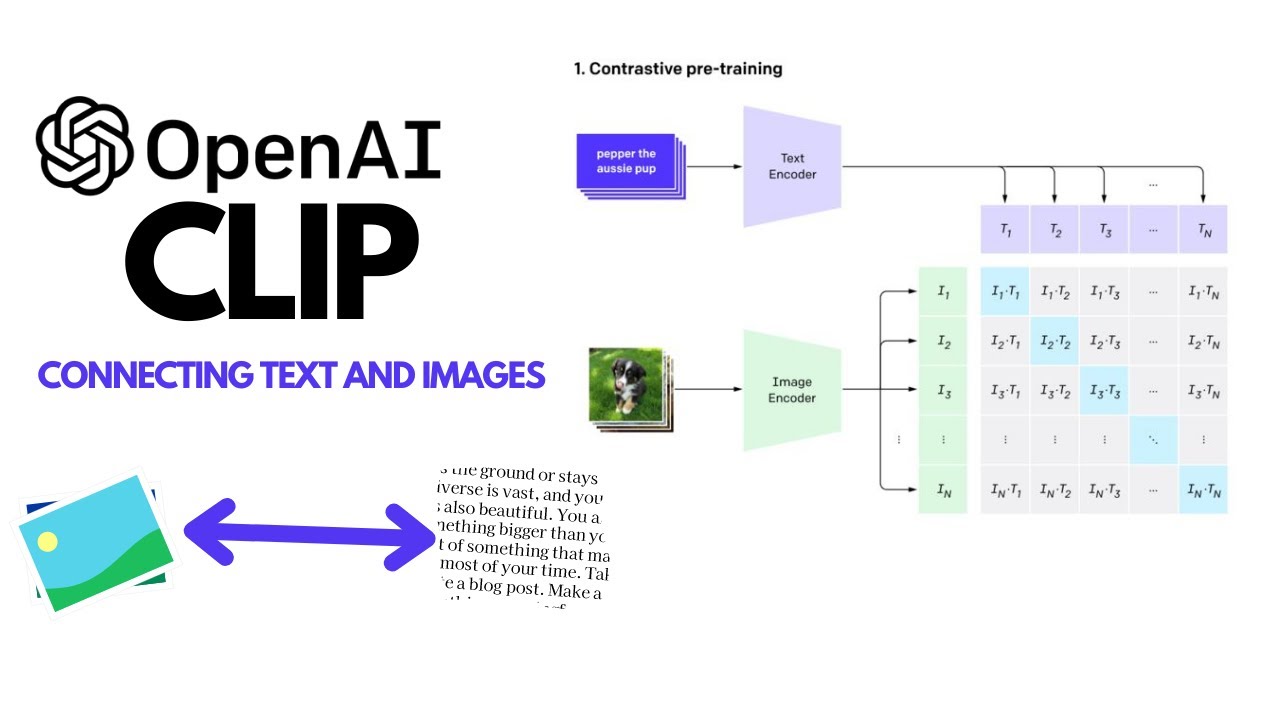
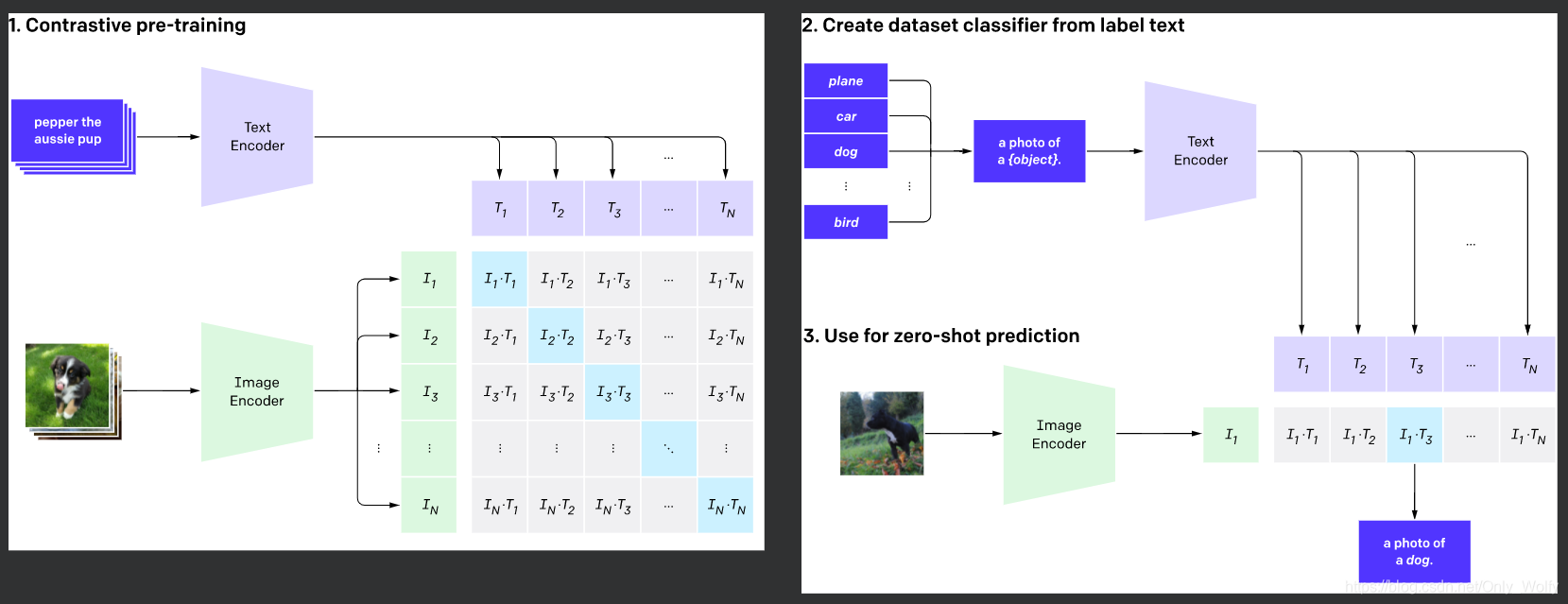
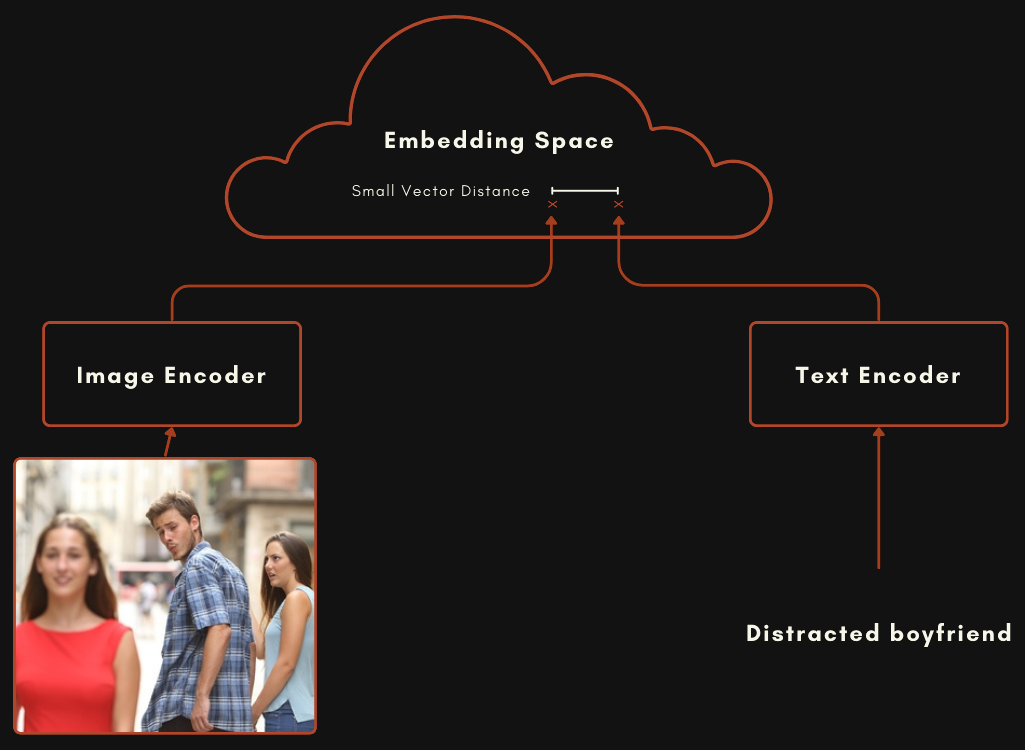
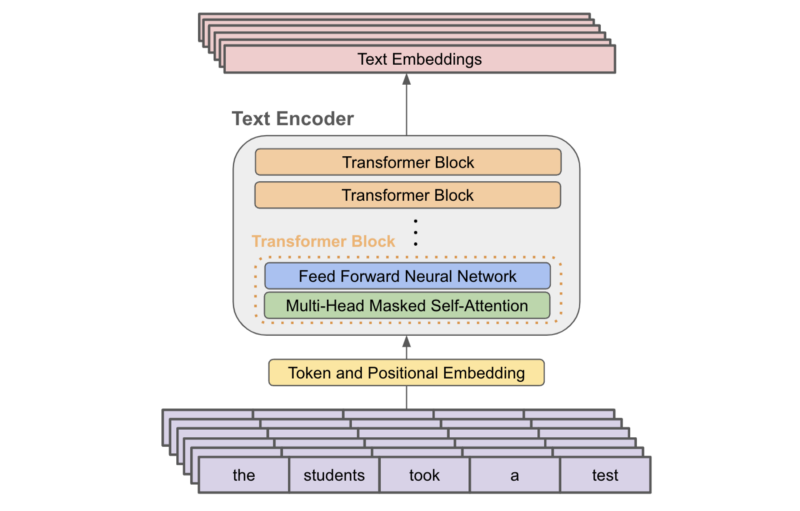
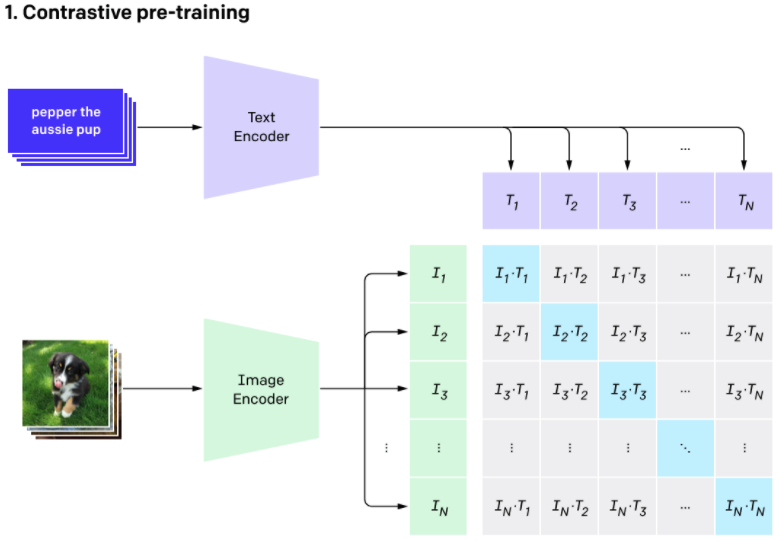
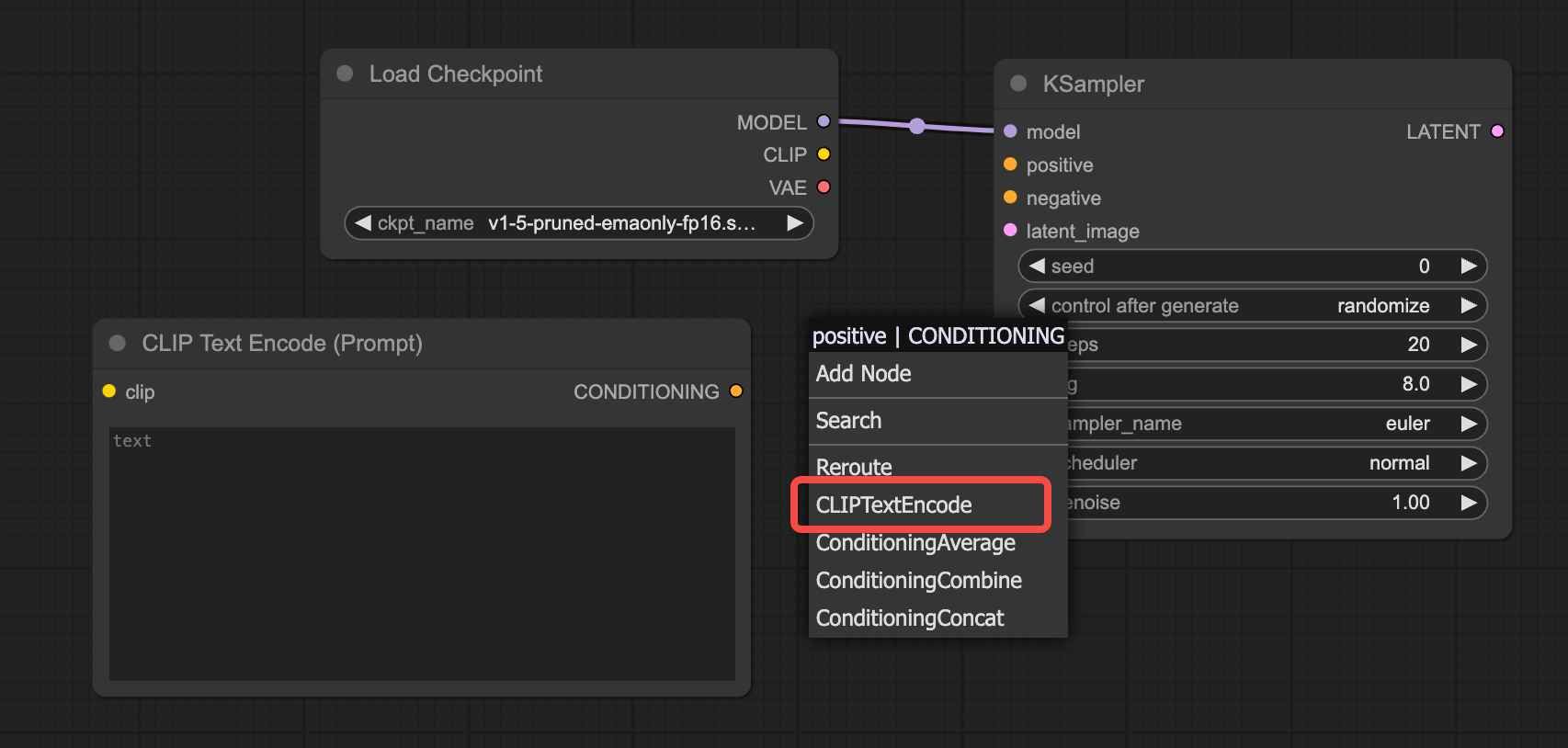
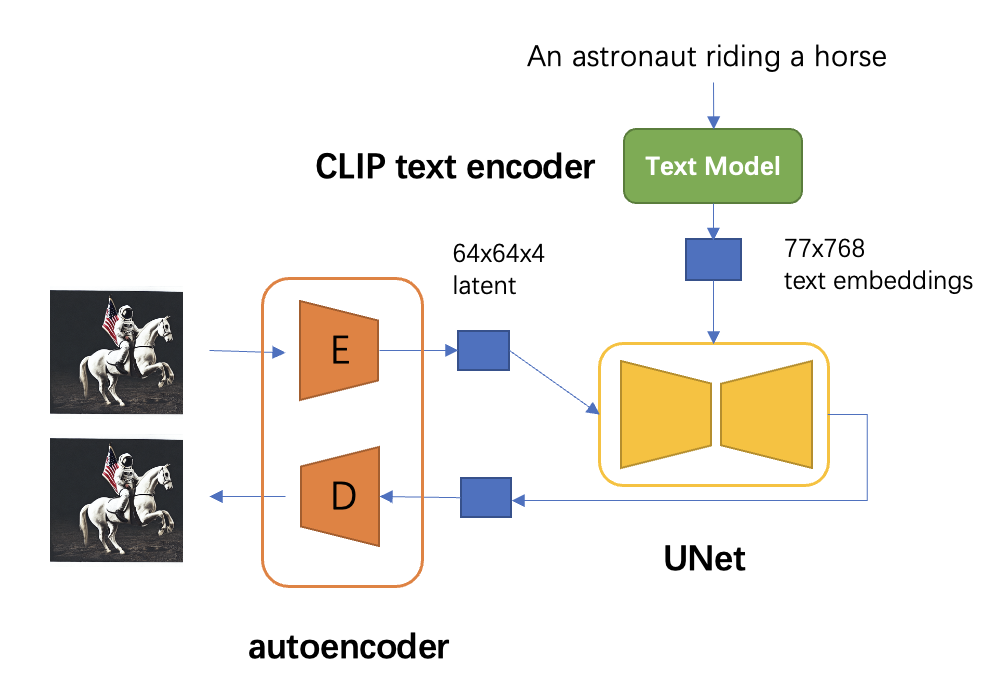
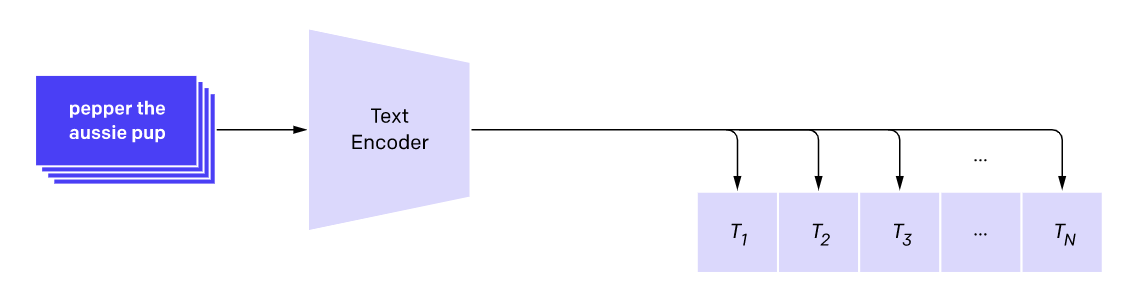
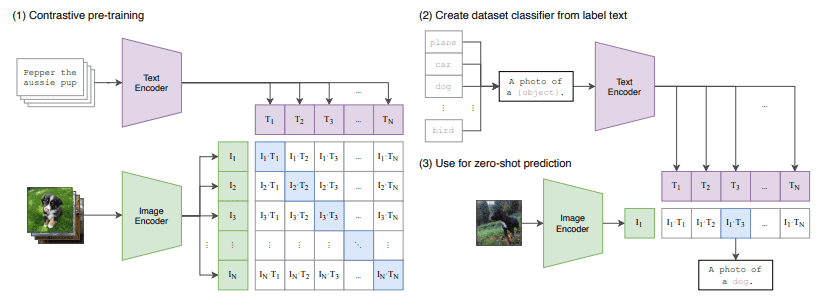
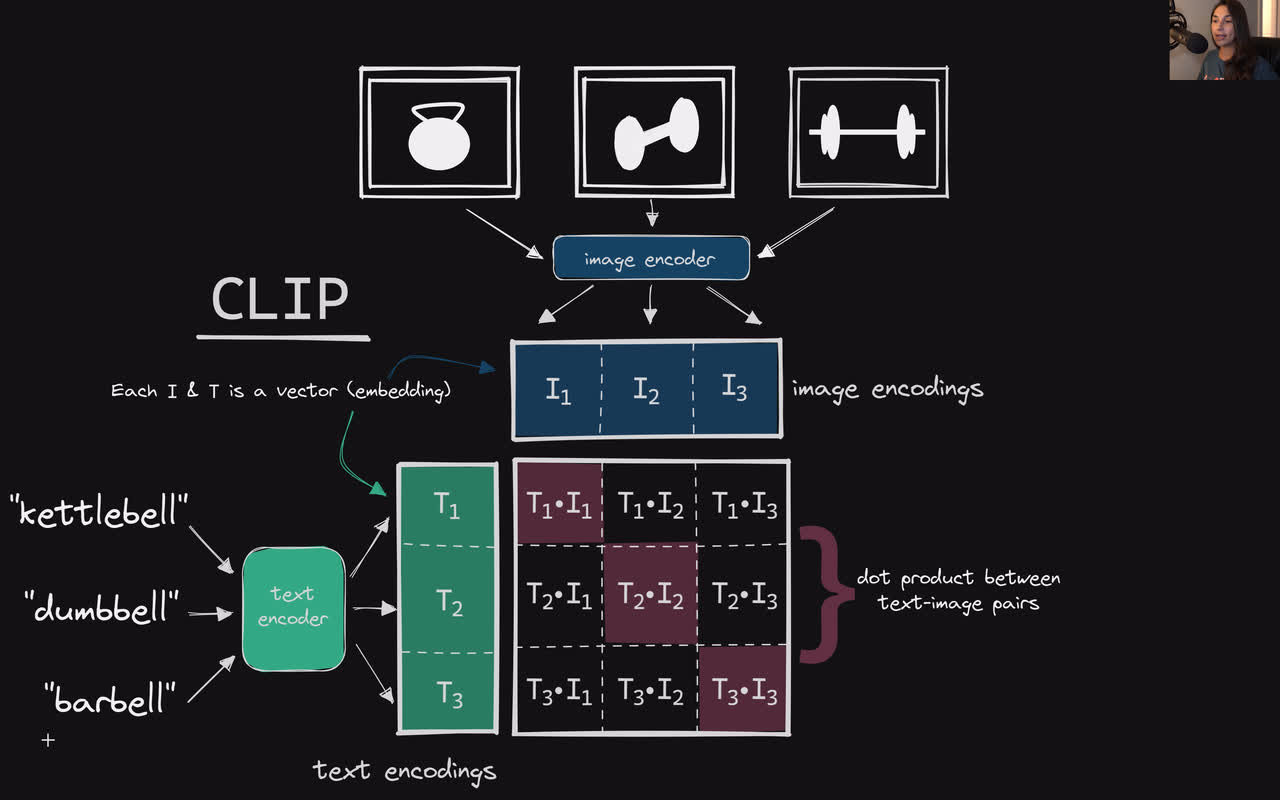
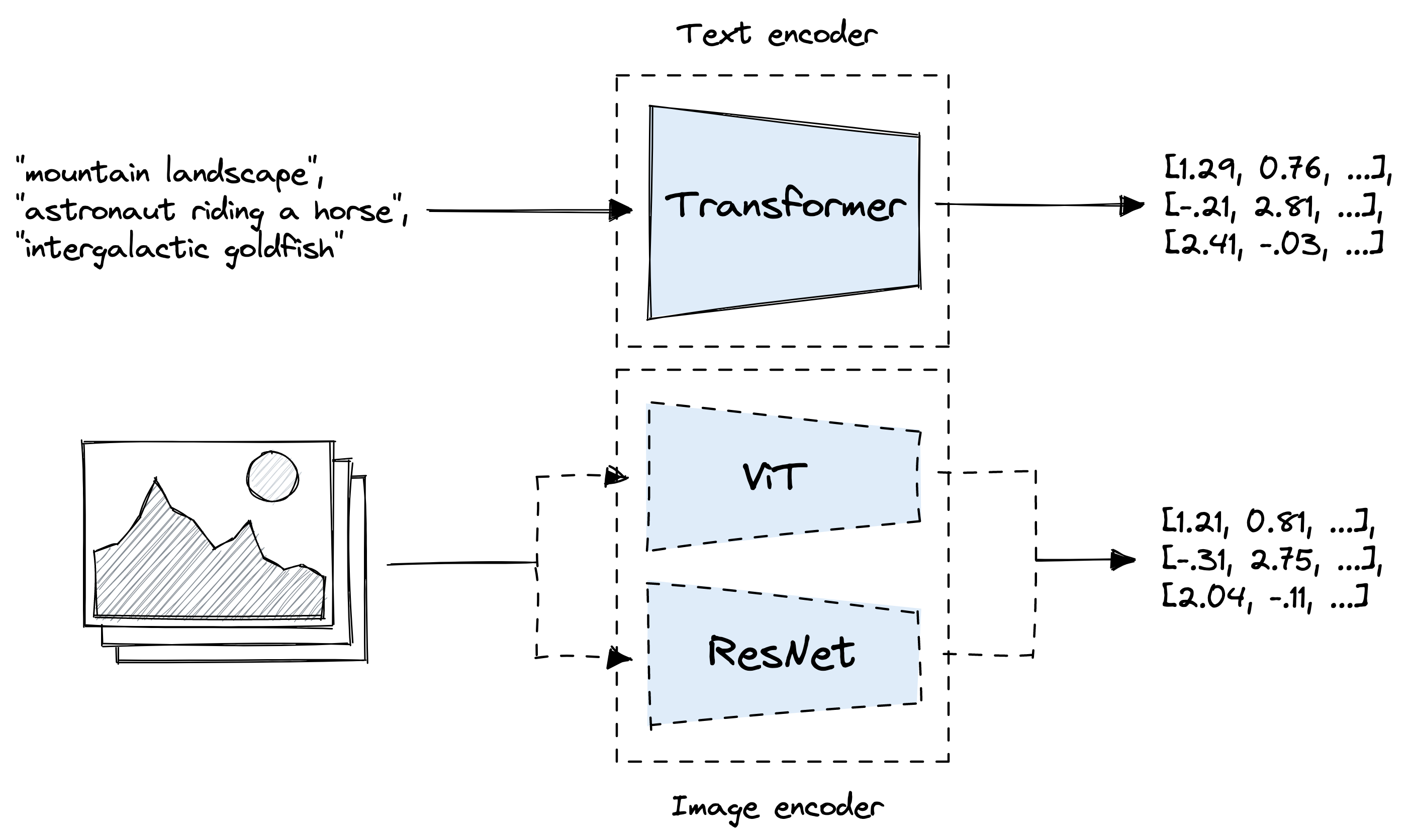
Example showing how the CLIP text encoder and image encoders are used ...
Text as Guidance for Diffusion Models - CLIP Text Encoder - deeplizard
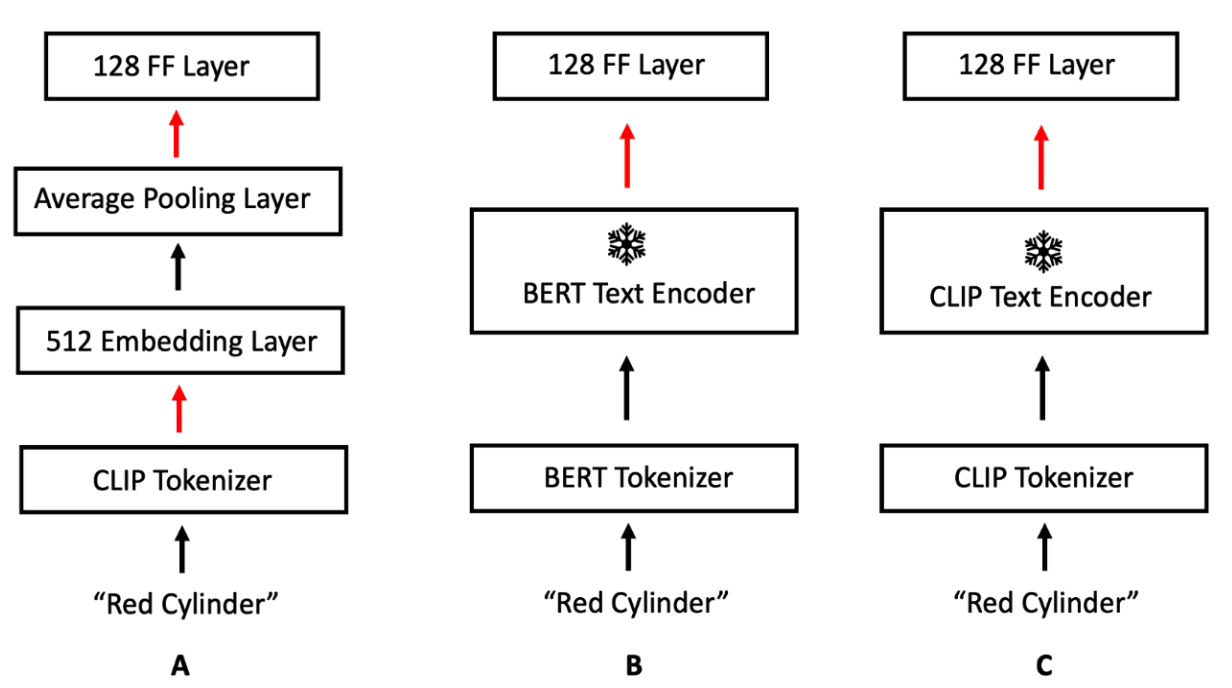
Importance of text encoder using CLIP vocabulary on 75% train split ...
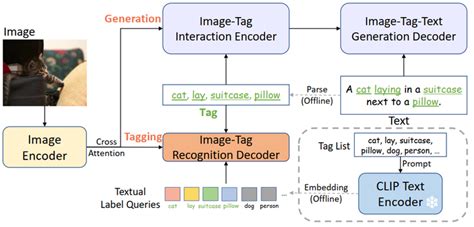
Overview of our proposed KKLIP. KKLIP has six models: CLIP text encoder ...
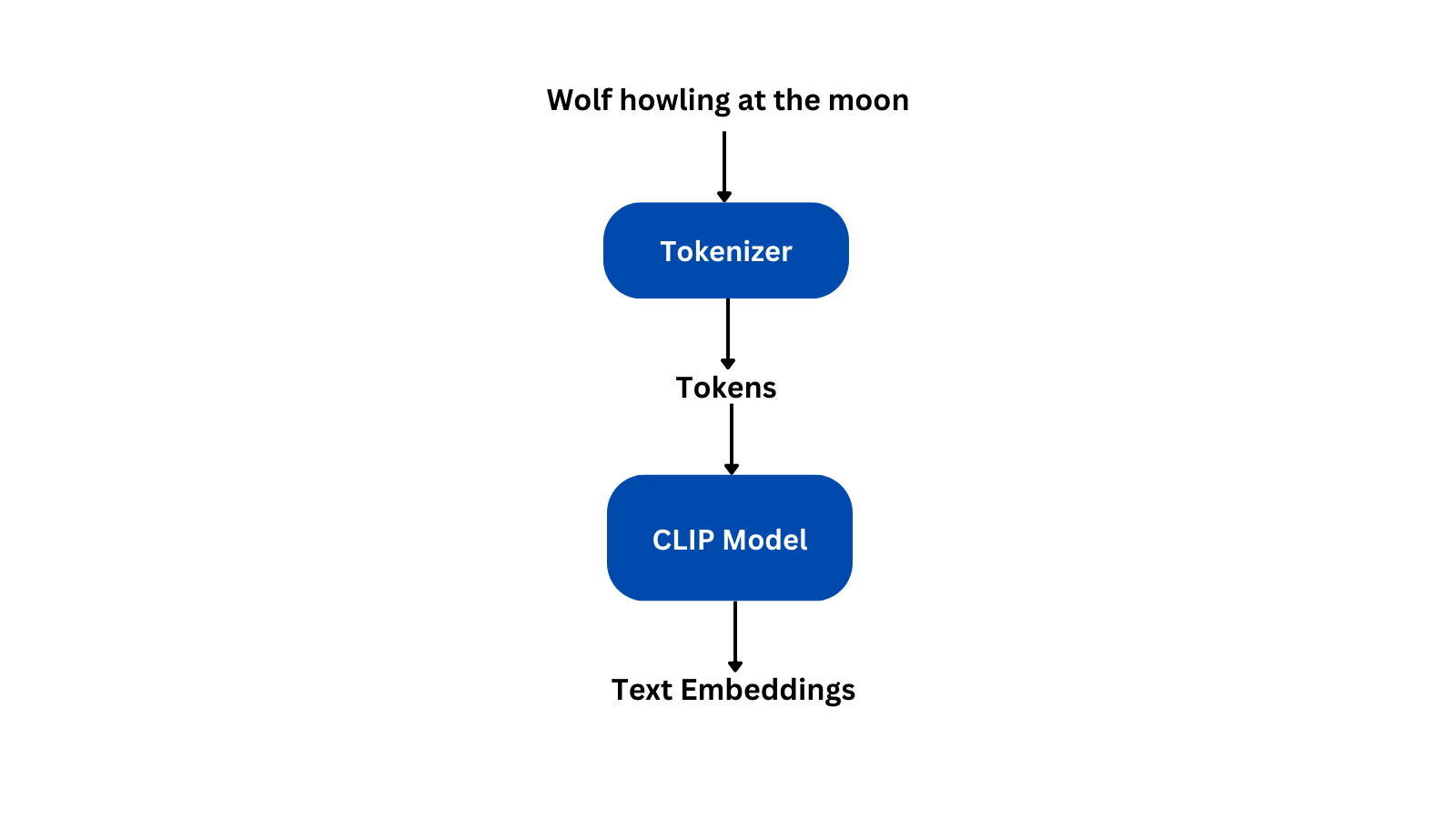
MLX CLIP Text Encoder
Why is there a difference in the text encoder between CLIP and open ...
Use fp8 Clip Text Encoder · Issue #80 · kijai/ComfyUI-WanVideoWrapper ...
Bridging the Gap Between Text and Images in Computer Vision With CLIP ...
Stable Diffusion核心网络结构——CLIP Text Encoder - 技术栈
GitHub - FreddeFrallan/Multilingual-CLIP: OpenAI CLIP text encoders for ...
(PDF) Turning a CLIP Model into a Scene Text Detector
CLIP Text Encoder-CSDN博客
Overview of VT-CLIP where text encoder and visual encoder refers to the ...
How to get all the features of the image encoder and text encoder ...
Unlocking the Power of CLIP Encoder: A Text Encoder's Impact
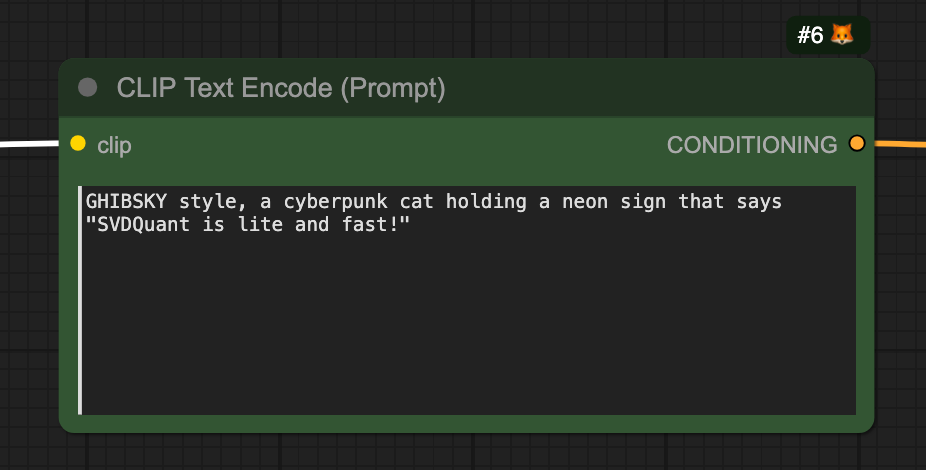
CLIP Text Encode (Prompt) - ComfyUI Community Manual | PDF
【论文阅读】Turning a CLIP Model into a Scene Text Detector-CSDN博客
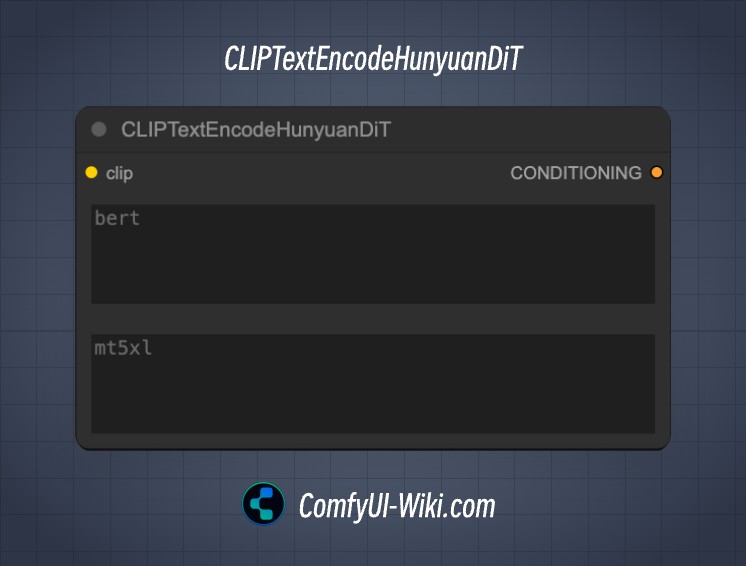
CLIP Text Encode Hunyuan DiT | ComfyUI Wiki
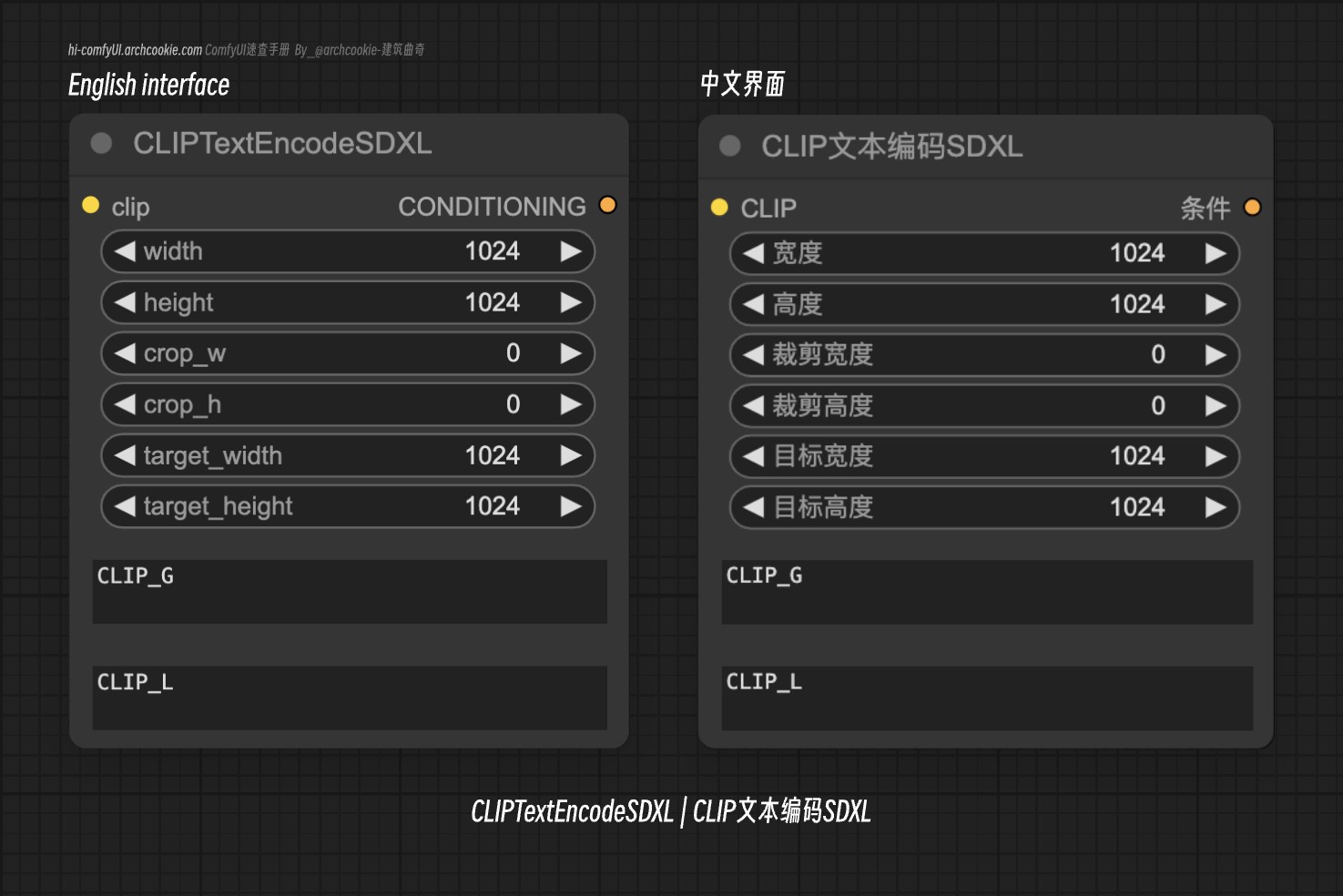
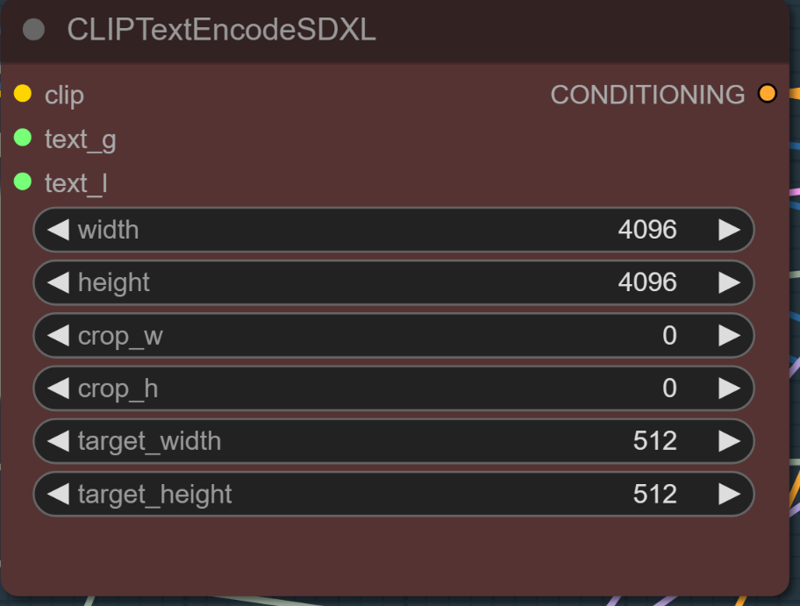
CLIP Text Encode SDXL | ComfyUI Wiki
How is the text encoder initialized? · Issue #267 · openai/CLIP · GitHub
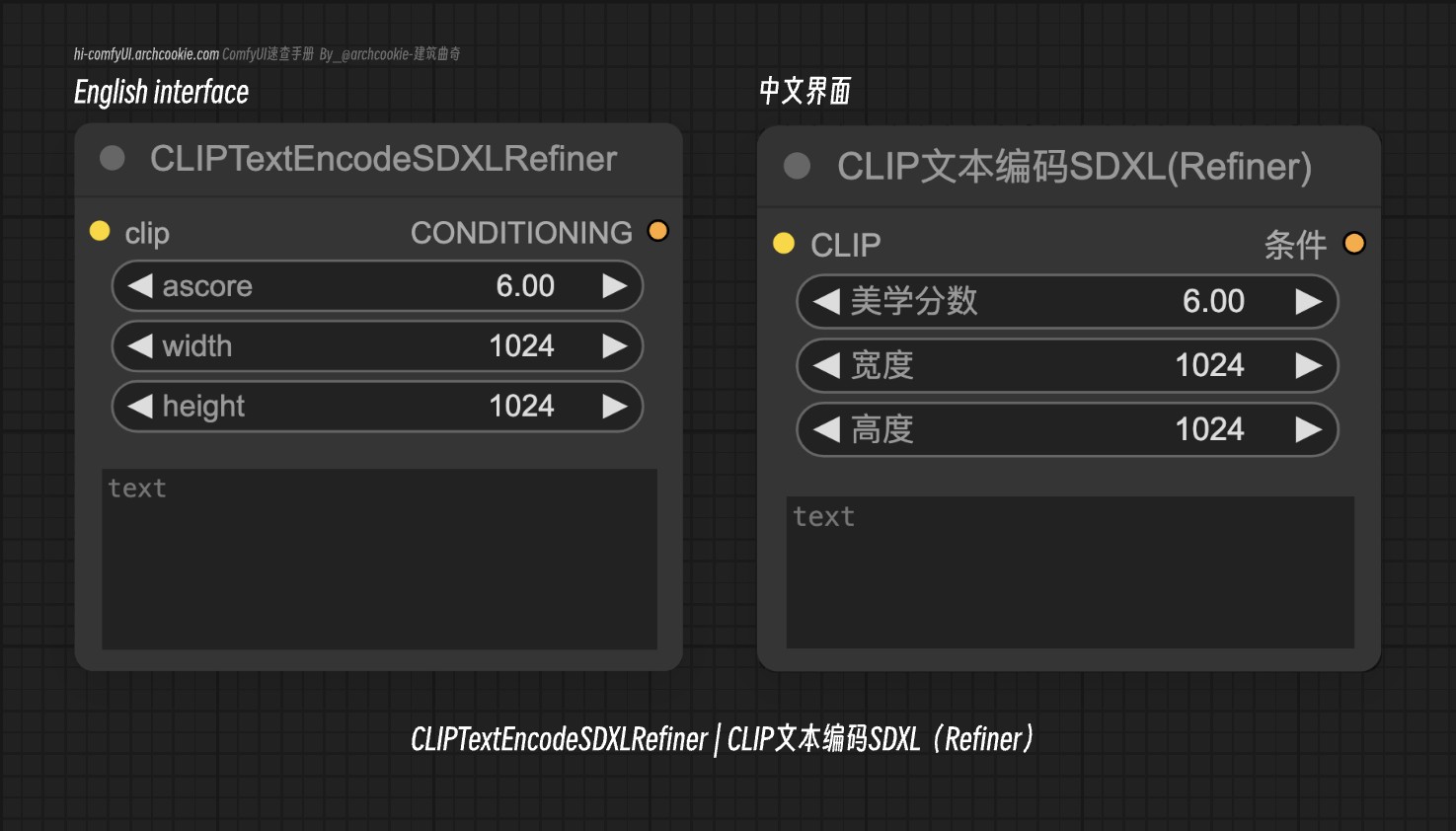
CLIP Text Encode SDXL Refiner | ComfyUI Wiki
(PDF) Turning a CLIP Model into a Scene Text Spotter
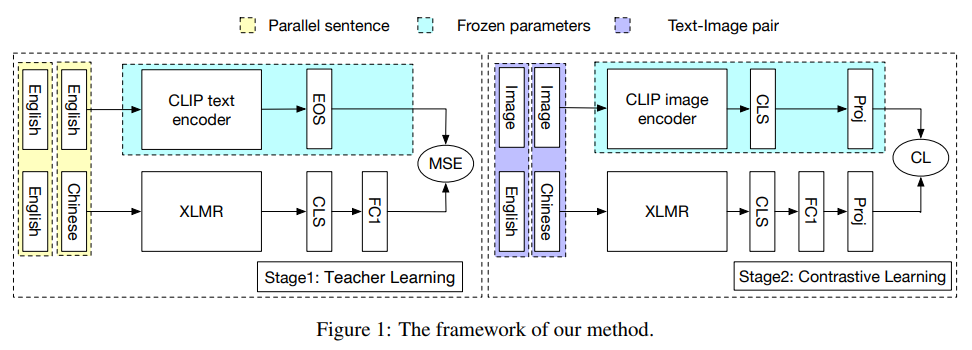
[논문 리뷰]AltCLIP: Altering the Language Encoder in CLIP for Extended ...
The text encoding (left) and deconding (right) algorithm | Download ...
Simultaneous training of the text and image encoder to learn visual ...
On the Brittleness of CLIP Text Encoders | ResearchTrend.AI
Clip text encode SDXL and Refiner Params - v1.0 | Stable Diffusion XL ...
Creative Image Generation from Prompt Text Using CLIP and VQGAN Models ...
Stable Diffusion核心网络结构——CLIP Text Encoder-CSDN博客
Multi-modal ML with OpenAI's CLIP | Pinecone
CLIP (Contrastive Language-Image Pretraining) - GeeksforGeeks
Method 1/2 for using CLIP in domain. Specifically, the text/image ...
Image–Text Matching Model Based on CLIP Bimodal Encoding
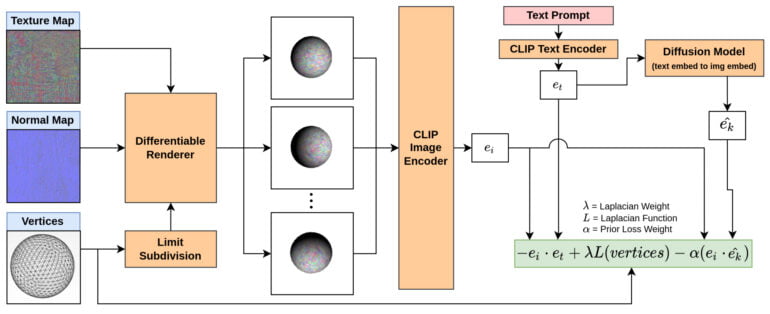
CLIP-Mesh: AI generates 3D models from text descriptions
《CLIP:Connecting text and images》论文学习 - 郑瀚 - 博客园
Clip Architecture Definition at Tracy Macias blog
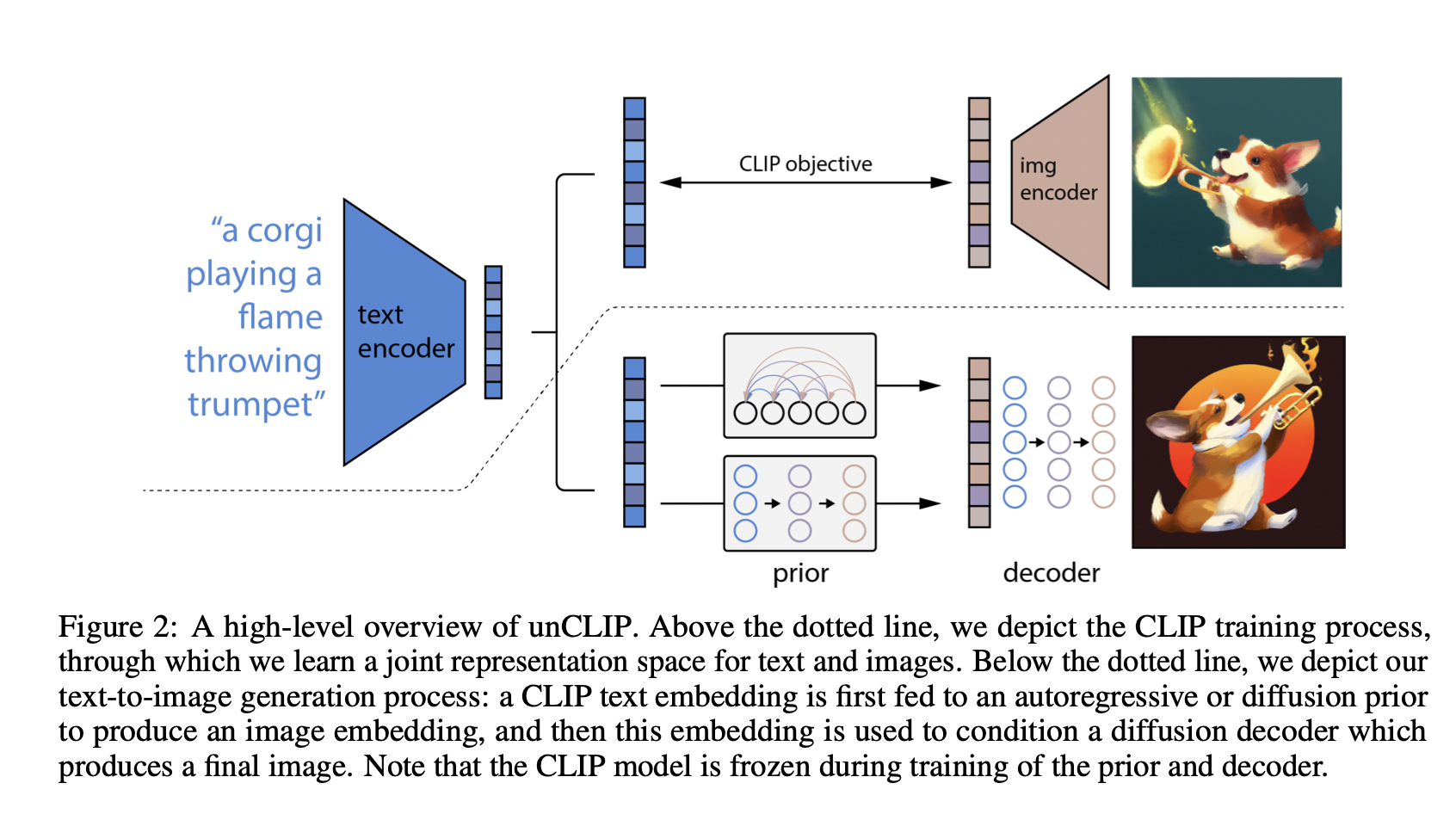
(PDF) Hierarchical Text-Conditional Image Generation with CLIP Latents
ComfyUIのプロンプト(ポジティブ・ネガティブ)の使い方、CLIP Text Encodeについて | すなぎつ
Zero-shot Image Classification with OpenAI's CLIP | Pinecone
GitHub - jina-ai/executor-text-clip-encoder: Encode text into ...
GitHub - tanwanirahul/CLIP_from_scratch: OpenAI's CLIP model ...
OpenAI's CLIP Explained and Implementation | Contrastive Learning ...
CLIP: Connecting Text and Images 介绍-CSDN博客
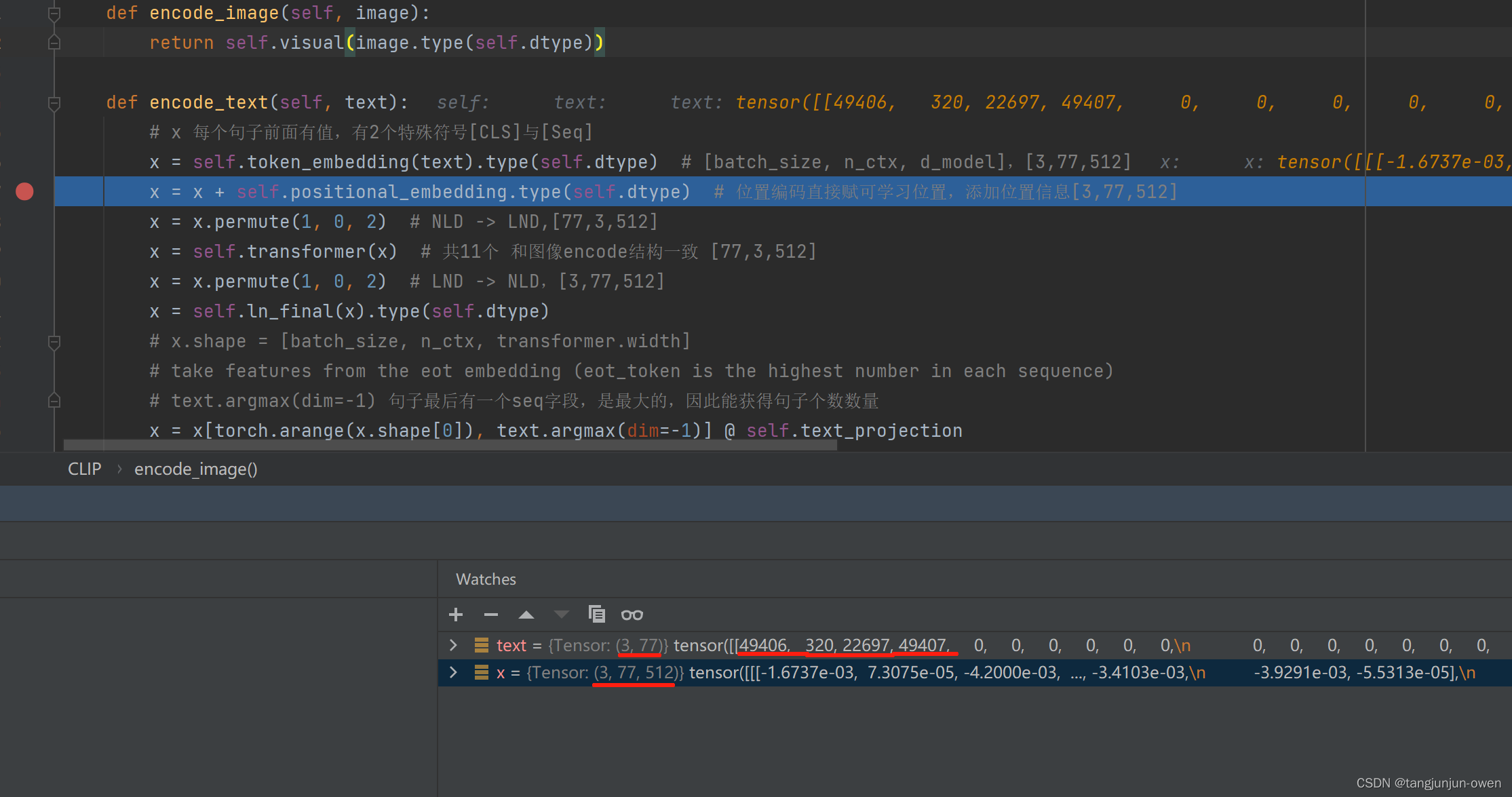
encode_text gives different clip features for the same text, single ...
Text-Driven Image Manipulation/Generation with CLIP | by 湯沂達(Yi-Dar ...
[간단정리] Hierarchical Text-Conditional Image Generation with CLIP Latents ...
Multi-Task Video Captioning with a Stepwise Multimodal Encoder
Illustration of object text extraction where Encoding, Embedding, and ...
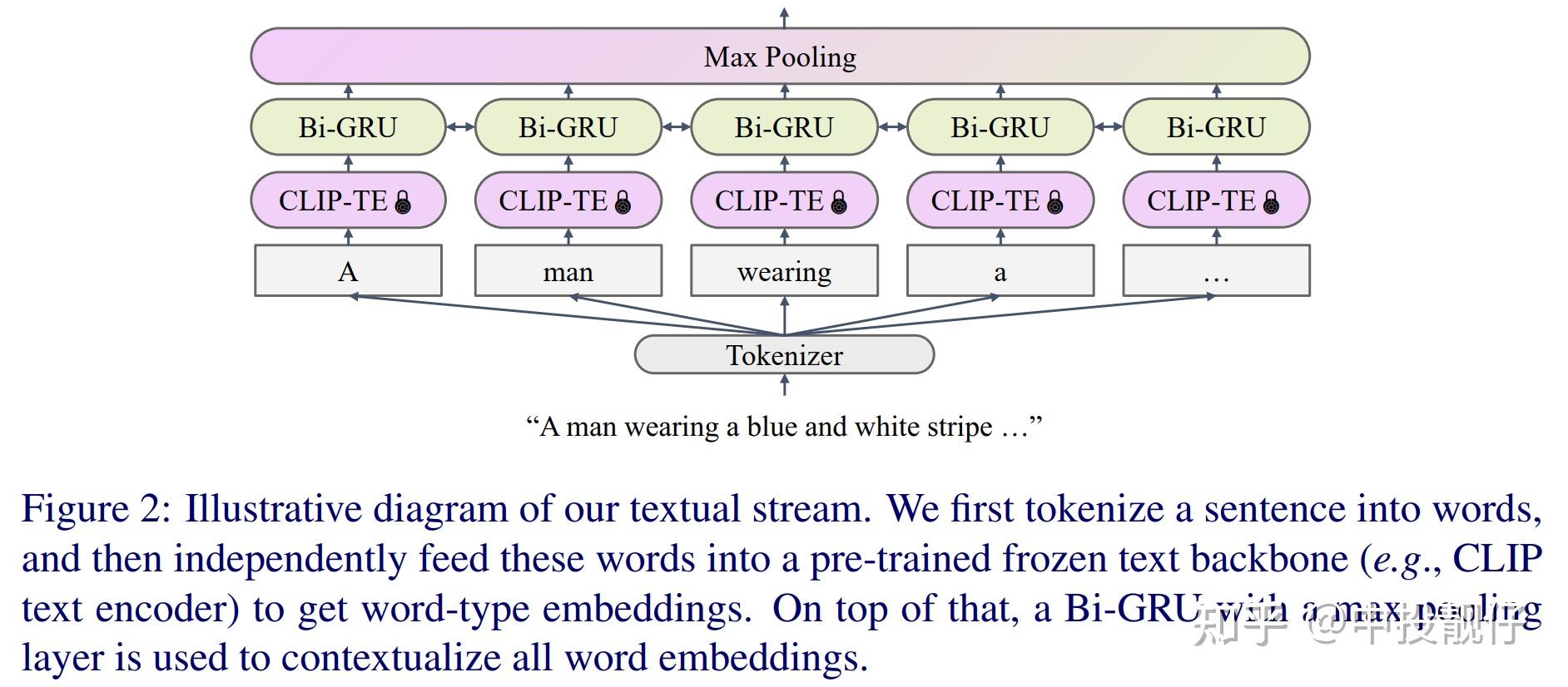
Adapting CLIP for Action Recognition via Dual Semantic Supervision and ...
CLIPS: An Enhanced CLIP Framework for Learning with Synthetic Captions
CLIP 改进工作_clip改进-CSDN博客
The What and Why of Text-Image Modality Gap in CLIP Models
【DL輪読会】Hierarchical Text-Conditional Image Generation with CLIP Latents ...
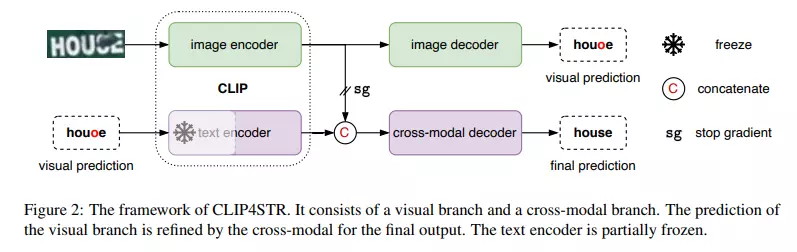
Paper reading | CLIP4STR: A Simple Baseline for Scene Text Recognition ...
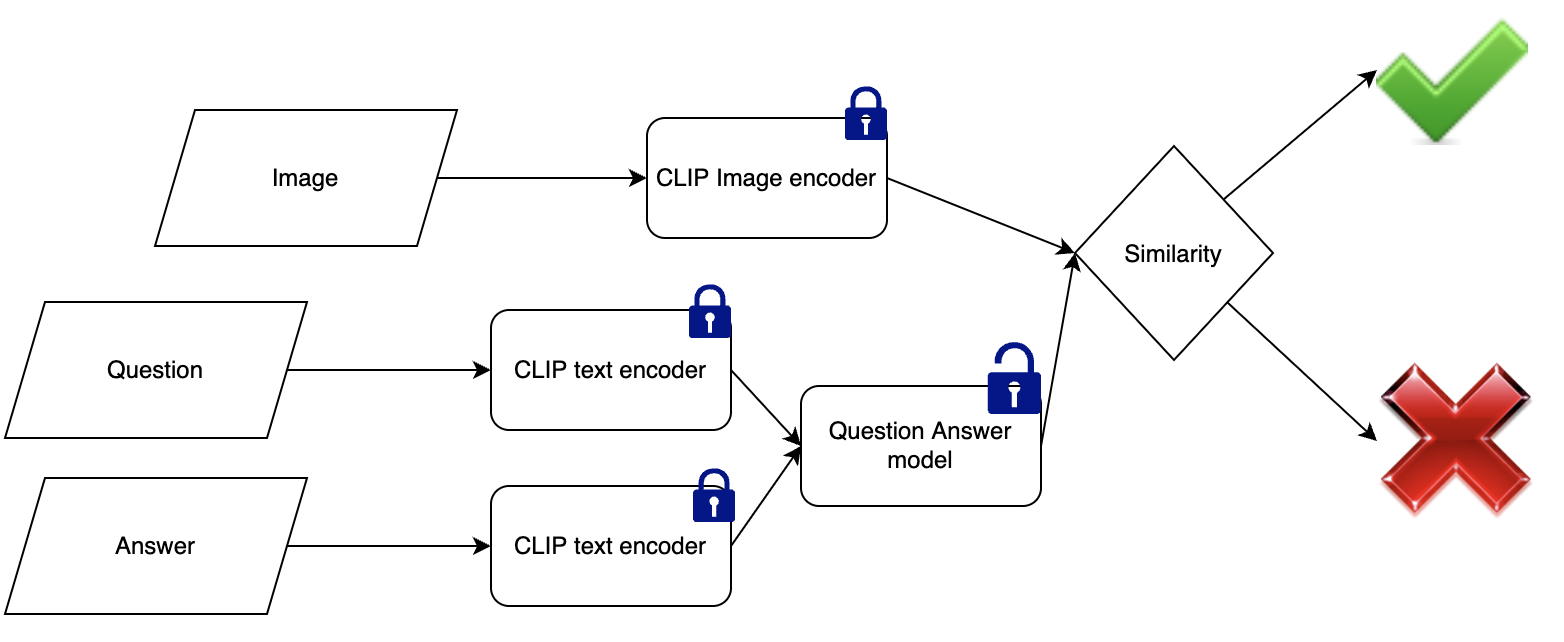
Visual Question Answering using CLIP - Ashwin’s
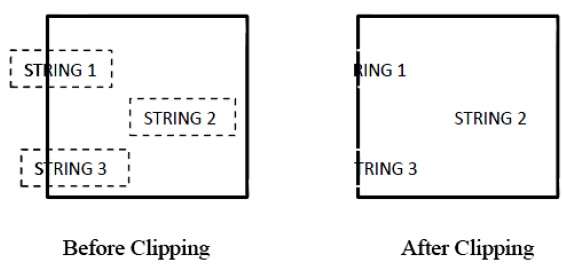
Curve and text clipping | PPTX
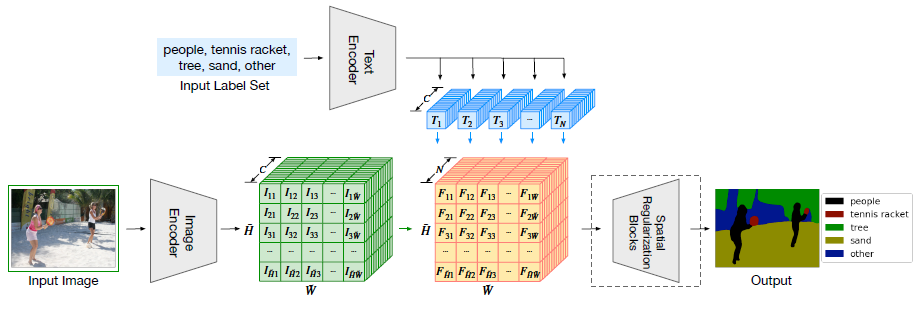
Overview of our method. The image is encoded into a feature map by the ...
Vision Transformers: From Idea to Applications (Part Four)
CLIP, Intuitively and Exhaustively Explained | Towards Data Science
CLIP, leveraging the power of a large image-text paired dataset for ...
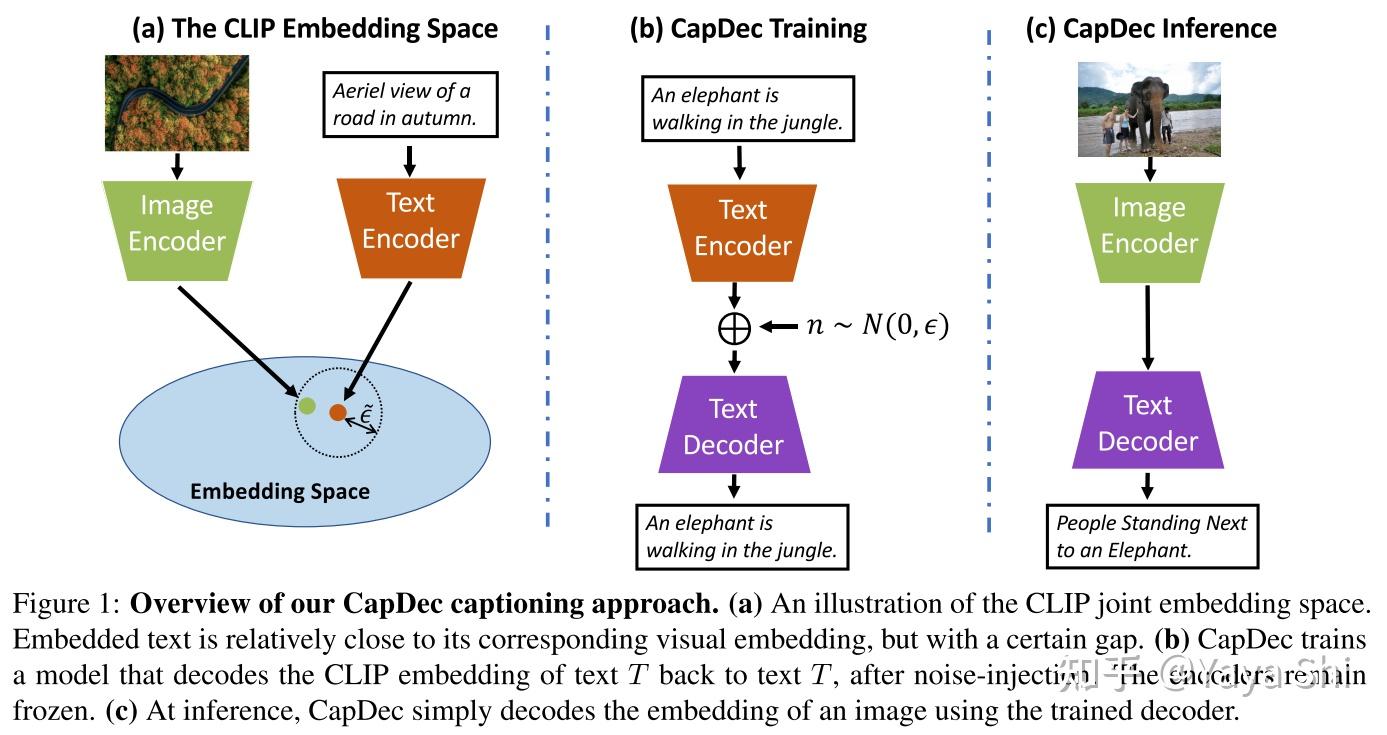
[论文阅读] Text-Only Training for Image Captioning using Noise-Injected ...
详解多模态CLIP算法原理与代码实现-开发者社区-阿里云
CVPR 2023|白翔团队新作:借助CLIP完成场景文字检测-极市开发者社区
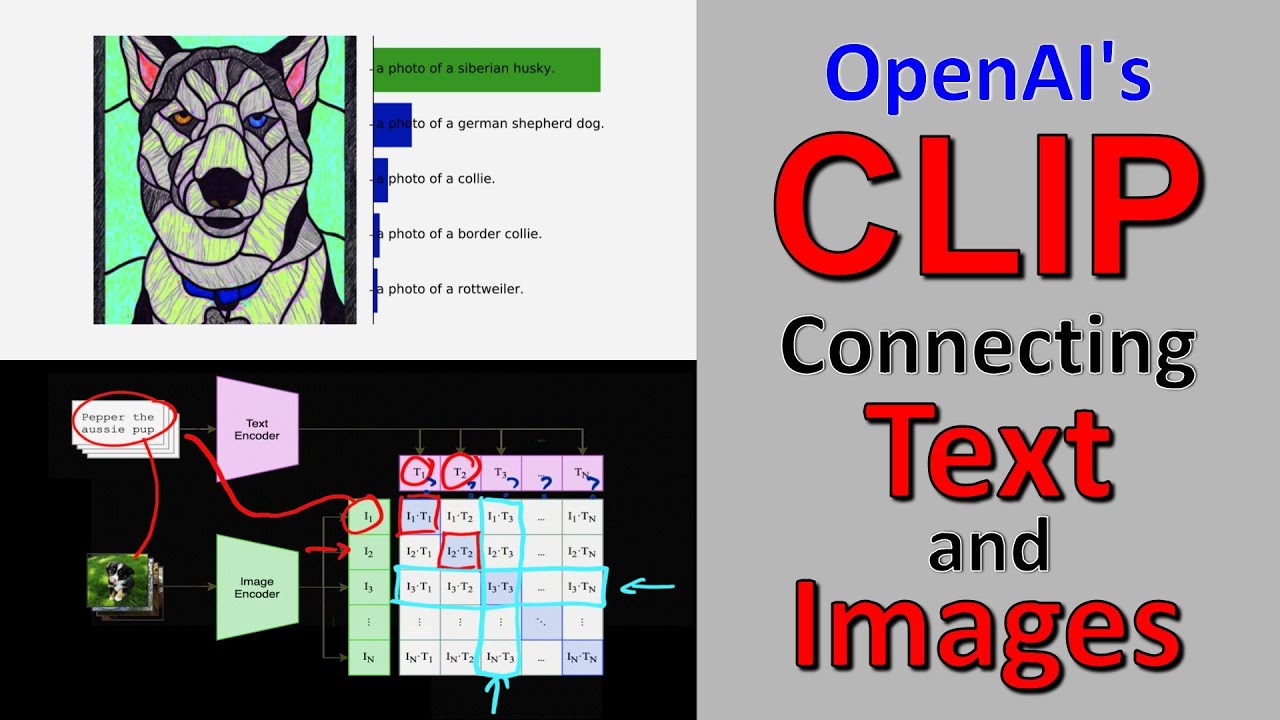
OpenAI CLIP: ConnectingText and Images (Paper Explained) - YouTube
CLIP/clip at main · openai/CLIP · GitHub
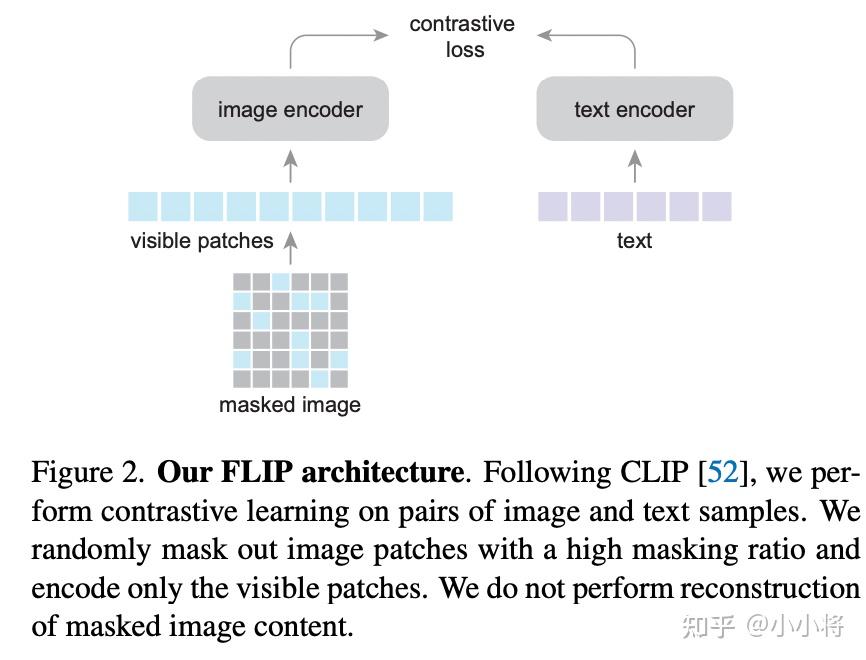
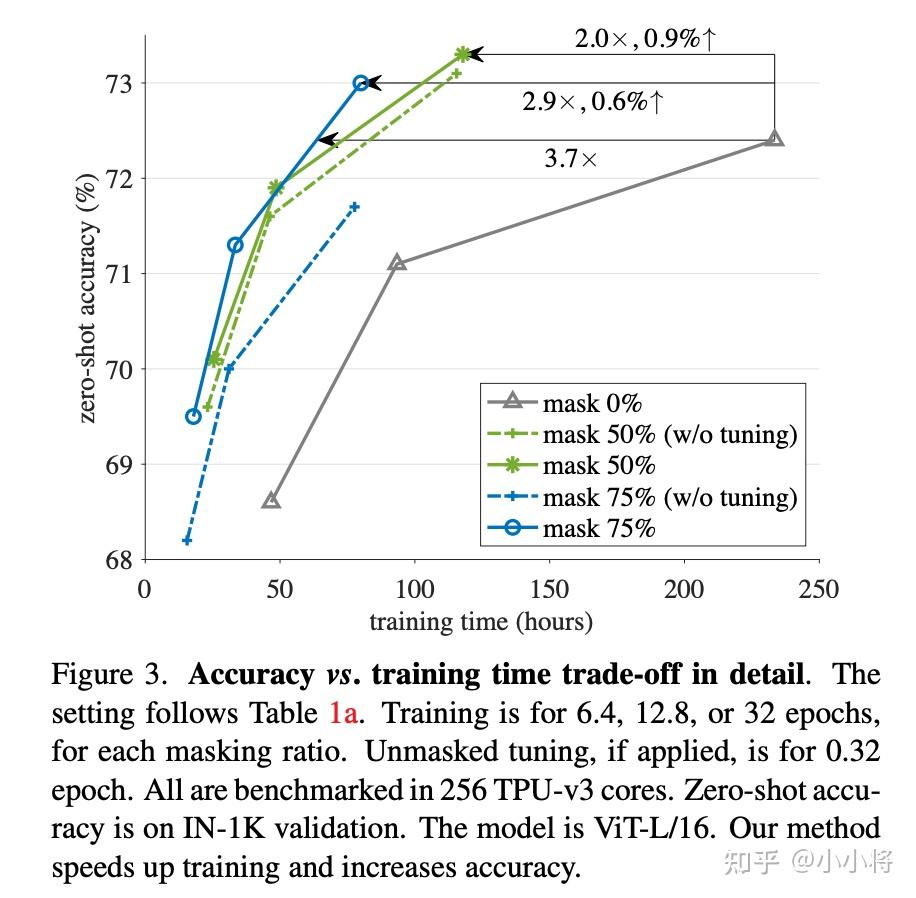
FLIP:通过图像掩码加速CLIP训练 - 知乎
Re-Structuring CLIP’s Language Capabilities - Sprocket Lab
LaraSg/CLIP-en-text-encoder at main
ComfyUI Beginner's Ultra-Detailed Guide - ComfyUI Tutorials - Learn How ...
详解一篇CLIP应用在语义分割上的论文_clip做语义分割在通用视觉领域-CSDN博客
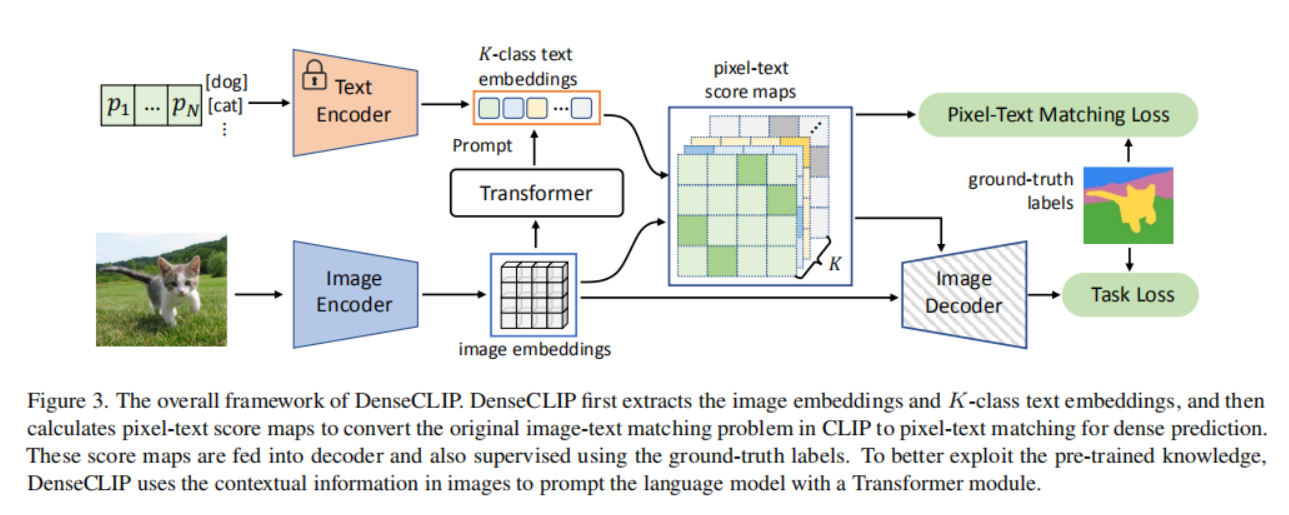
【论文阅读】DenseCLIP: Language-Guided Dense Prediction with Context-Aware ...
Comprehensive Guide for the ComfyUI User Interface
从理论到实践:CLIP原理,以及在 AI 图像与视频生成中是怎么被应用的 - 知乎
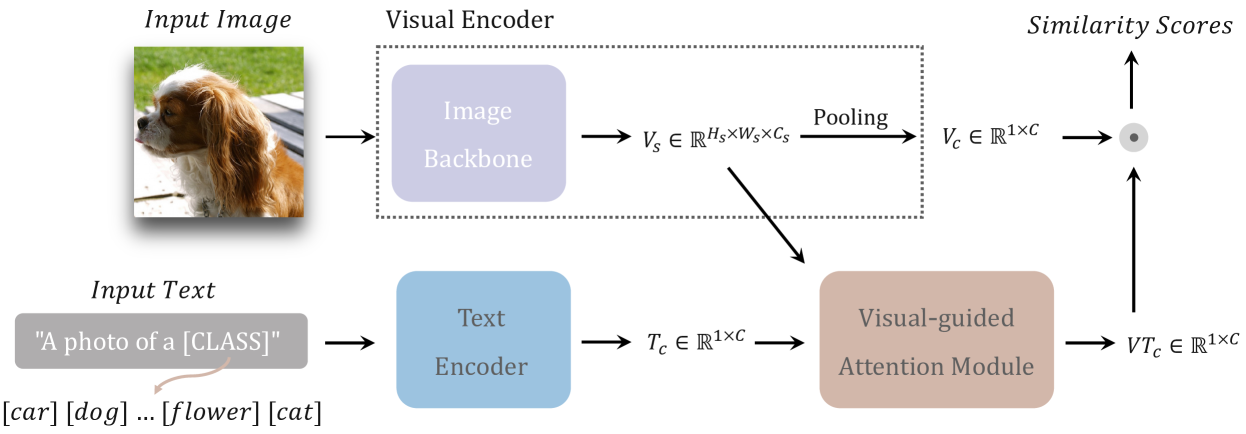
[2112.02399] VT-CLIP: Enhancing Vision-Language Models with Visual ...
3 research papers to understand text-to-image synthesis models better ...
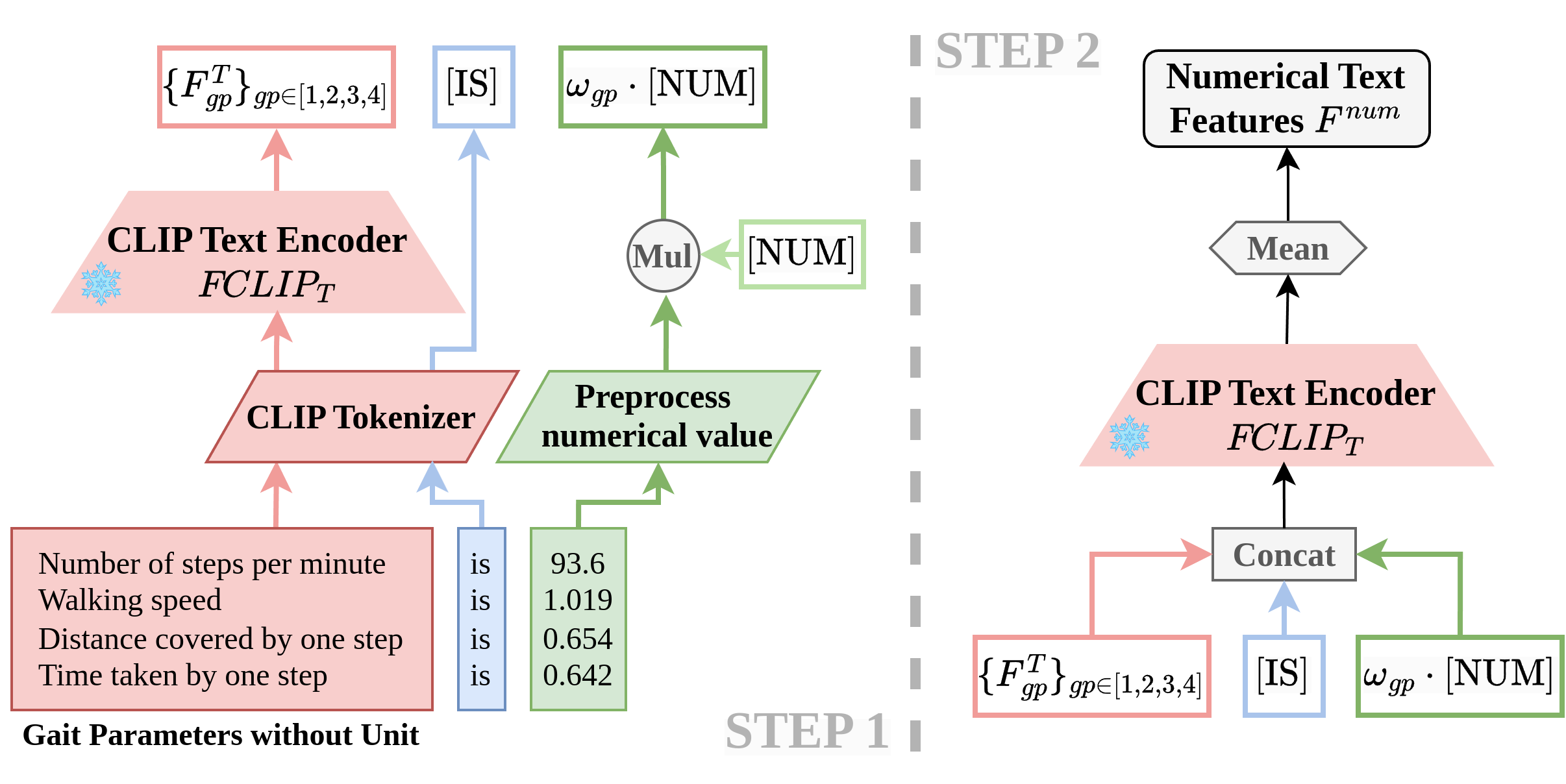
Enhancing Gait Video Analysis in Neurodegenerative Diseases by ...
Question about clip.encode_text · Issue #217 · openai/CLIP · GitHub
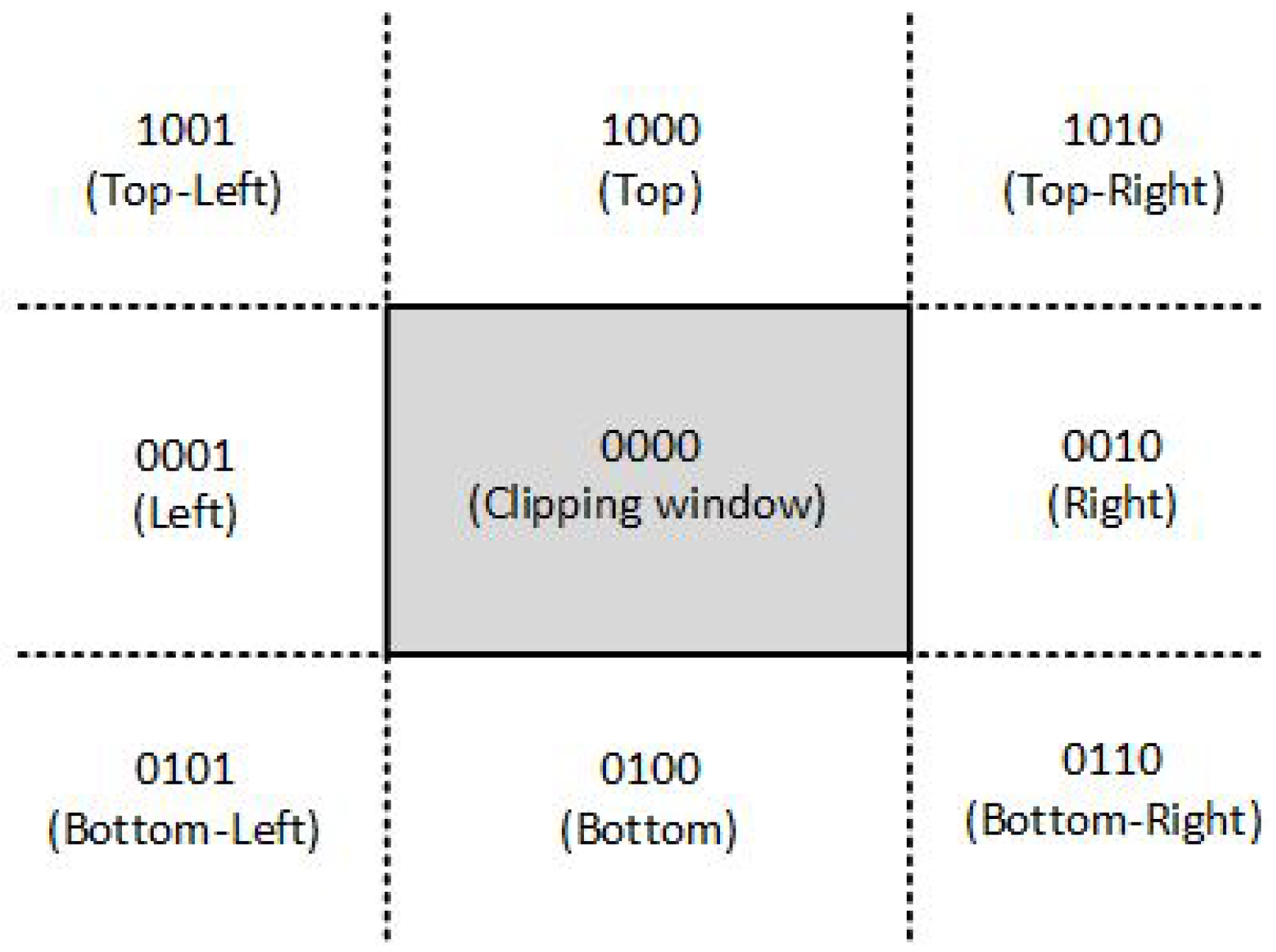
J. Imaging | Free Full-Text | Line Clipping in 2D: Overview, Techniques ...
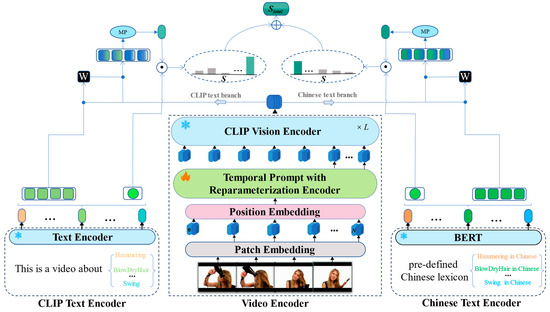
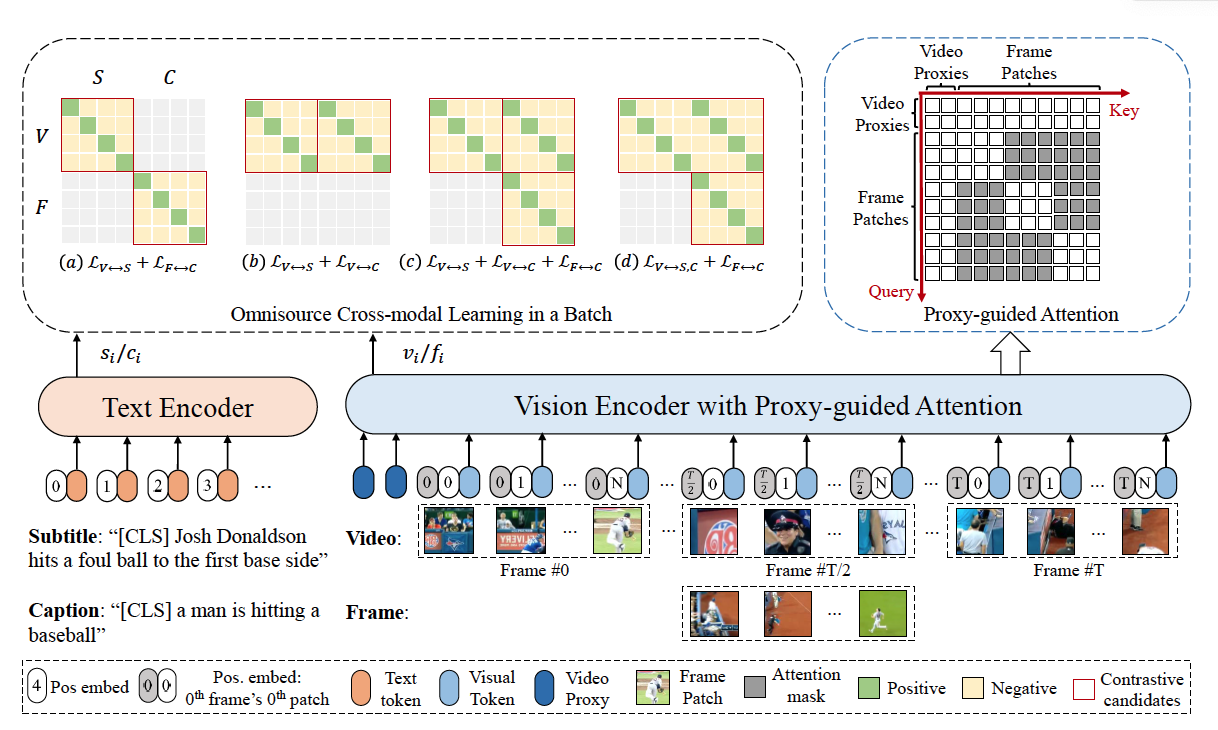
[MultiModal] CLIP-ViP: Adapting Pre-trained Image-Text Model to Video ...
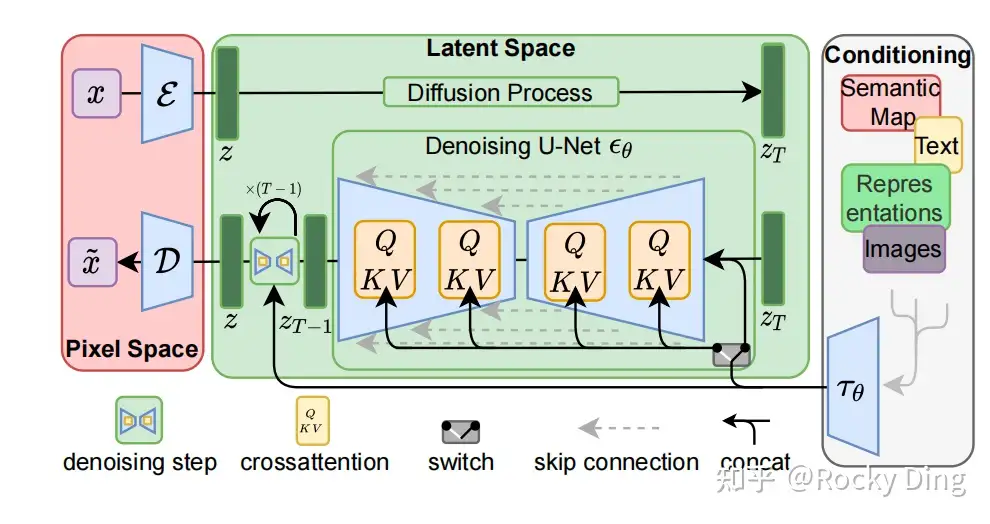
【Stable Diffusion原理】硬核解读Stable Diffusion(完整版)-CSDN博客
CLIP-based Image Editing | AI Tutorial | Next Electronics
论文解读(7)-CLIP_clip论文原文-CSDN博客
什么是CLIP文本编码器 | AIUG
Compositional Learning of Visually-Grounded Concepts Using ...
基于CLIP的细分赛道—Text Based Person Retrieval - 知乎
【04】ComfyUI基础 - 从CLIP文本编码器到提示词的高级应用 - 知乎
CLIP6-CSDN博客
2024不可不会的StableDiffusion之文本编码器(二)-CSDN博客
Overall pipeline of our proposed ZegOT for zero-shot semantic ...
Channeling Creativity Through a Deeper Understanding of AI Image Generation
AwesomeCLIP---100+篇CLIP相关工作整理 - 知乎
Theory and Application of Image Generation.
CLIP模型原理与代码实现详解-CSDN博客
Mozilla AI Guide
Viewing & Clipping – QCOM
Vision Language models: towards multi-modal deep learning | AI Summer
GitHub - yubin1219/text2image_manipulation: Multimodal Learning - using ...
Getting Started in the World of Stable Diffusion | Bipin



















.png)